Activity
Mon
Wed
Fri
Sun
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
What is this?
Less
More
Memberships
Data Alchemy
Public • 22.2k • Free
The Growth Project
Private • 543 • $1/m
AI Automation Elite
Private • 204 • Free
Software Developer Academy
Private • 20k • Free
Skool Masterclass (Free)
Private • 86.6k • Free
AI Automation Agency Hub
Private • 50.4k • Free
59 contributions to Data Alchemy

20d ago in
Studying Together: Understanding Measures of Central Tendency
Hi fellow Data Alchemists, I’m writing here with the goal of studying together the essentials we need to know if we want to become Data Scientists or work with Machine Learning. I’m considering creating a series of posts covering Statistics, Probability, and maybe even some Math needed for Machine Learning. I’m not an expert, so I’ll be gathering information from the web, I'll write the post and I'll ask ChatGPT to correct me. My idea is to create some accountability for myself while sharing my studies with all of you. Today, I thought I’d start with the basics: Measures of Central Tendency. As the title suggests, "Central Tendency" should already give us a hint about what this is about, right? If you're not sure, it’s simply a fancy term for describing the mean, median, and mode. So, what are Measures of Central Tendency? They’re key statistical tools that help us summarize and understand the central point of a dataset. These measures are especially useful in data science for interpreting data distributions and providing meaningful insights into the general behavior of the data. The three primary measures, mean, median, and mode, each give us a unique perspective on this “center.” - Mean: The mean is calculated by summing up all data points and dividing by the count of those points. It’s useful when data is symmetrically distributed, as it represents the expected value. However, it’s sensitive to outliers, so in skewed distributions, it might not accurately represent the center of the data. - Median: The median, or the middle value when data is ordered, is especially valuable in skewed distributions or when there are outliers. Since it reflects positional rather than magnitude-based centrality, it often provides a more robust measure of central tendency than the mean in non-normal distributions. - Mode: The mode, or the most frequently occurring value, is useful in categorical data or multimodal distributions. It offers insights into the most common category or value in the dataset, which can be particularly important for understanding customer preferences, product popularity, or common patterns in discrete data.
21
19
New comment 13h ago


3 likes • 4d
It is a really great introduction to statistics. 🙂
20d ago in
Exploring Image Segmentation: Sharing My Second Computer Vision Exercise
Hi everyone, I just realized it’s been almost a month since I posted my first exercise! I was a bit hesitant to share this one, it actually took me two weeks to decide—but I thought I’d go ahead and post it anyway. This time, I'm experimenting with image segmentation, as part of a series of seven exercises I’m working on to dive into computer vision. For those who read my previous post, you might remember I’m following some ideas ChatGPT suggested for practical exercises in computer vision. I was unsure about sharing this one because I didn’t always get the outcome I expected: in some images, I managed to capture the entire edge of the leaf, while in others, I only segmented parts of it. Still, it was an interesting challenge, and I learned a lot from the process. Here’s what I focused on for this exercise: 2. Image Segmentation Objective: Explore techniques to divide an image into segments, or regions of interest. Tools: OpenCV, Scikit-Image. Exercises: - Apply thresholding techniques (binary, adaptive) - Use Otsu's method for automatic thresholding - Perform image segmentation using the Watershed algorithm - Experiment with contour detection Example Project: Segment different objects in an image (e.g., finding and counting coins) [Link to the notebook] Previous post if you did not read it: post By the way, my next exercise might take a bit longer as I am working on another project that I expect to share soon. I hope you all have a great week ahead! And please, if you have any comments on my notebook, I’d love to hear your thoughts on what I could improve or try differently.
8
2
New comment 1d ago
1 like • 4d
You inspire me to start computer vision exercises, too,
17d ago in
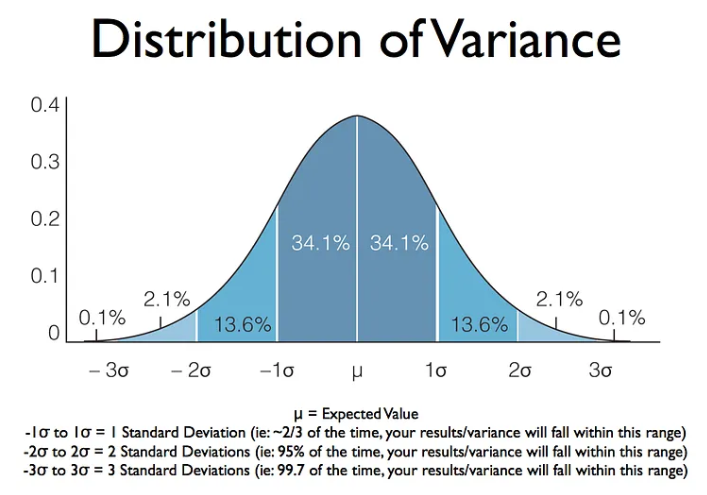
Learning Together: Understanding Variance
Hello, Data Alchemists! As promised, here’s the next step in our journey of learning statistics together. In our first post, we covered measures of central tendency (mean, median, and mode), and now we’re diving into measures of variability. Measures of variability reveal how spread out or diverse the values in a dataset are, giving us insight into the consistency or dispersion in the data. Knowing how much variation exists can reveal patterns and help guide decisions. To understand variability, we’ll look at three key measures: variance, standard deviation, and the interquartile range (IQR). In this post, we'll talk about variance. Variance: A Measure of Spread Variance measures how much the values in a dataset spread out around the mean. Essentially, it calculates the average of each data point’s squared difference from the mean. - What it tells us: Variance gives a sense of how spread out the data points are from the mean. High variance means data points are more widely spread (more variability), while low variance indicates that data points are closer to the mean, showing more consistency. - Example: Think of variance as the average “distance” of each value from the mean. For instance, in a class with test scores that are close to the average, the variance would be low. But if scores vary a lot (some very high, some very low), the variance will be high, reflecting this spread. Why Square the Differences for Variance? You might wonder why variance is calculated with squared differences instead of absolute differences, right? Well, here’s a brief answer: - Handling Negative Deviations: Squaring makes negative values positive, so deviations on either side of the mean contribute equally. - Emphasizing Larger Differences: Squaring highlights larger deviations from the mean, which makes outliers stand out more. - Foundation for Standard Deviation: The calculation of variance is crucial because it provides the basis for determining standard deviation, which quantifies how much the values in a dataset typically deviate from the mean. We’ll explore standard deviation in more detail in the next post, where we’ll see how taking the square root of variance gives us a more interpretable measure of spread that shares the same units as the original data.
8
2
New comment 1d ago
2 likes • 4d
Impressive and engaging writing for statistics. Variance can be an indicator of the range of values that you could expect to see in your data. So, during data cleaning, someone might notice high variability values, and cross-check if they are actual outliers.
4d ago in
Book Recommendations
Can you please leave any book recommendations that you might have here? I appreciate this 🙂
2
2
New comment 4d ago
4d ago in
Maybe the best code LLM out there
https://github.com/QwenLM/Qwen2.5-Coder
5
2
New comment 2d ago
1-10 of 59

@paraskevi-kivroglou-8113
Hey, I am Paraskevi! I am interested in exploring the capabilities of LLM models.
Active 4d ago
Joined Apr 2, 2024
powered by