Activity
Mon
Wed
Fri
Sun
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
What is this?
Less
More
Owned by Joshua
AI Explorers is a program focused on AI innovation, guiding participants through how to use AI to their advantage
We help Wealth Managers and Tax Planners utilize cutting edge technology to book more appointments with high net worth individuals & business owners
Memberships
CLOSED
Private • 9.7k • Free
GrowthOperator.com
Private • 50.8k • Free
Learn.AudienceLab.io
Private • 870 • Free
The No-Code Integrator
Private • 849 • $19/m
THP Jump Training
Private • 65.3k • Free
300 Saas
Private • 185 • Free
Skool Community
Public • 177.9k • Paid
AIpreneurs (Free)
Private • 5.1k • Free
14 contributions to AI Explorers

23d ago in
They Perplexitied GPT?! 🌐
Hey Team, Great news! ChatGPT now has a 'Search the Web' feature, allowing you to get real-time info directly in your chats. 💡 Stay current with the latest AI trends, tools, and insights ⚡ Instant problem-solving by pulling fresh resources from the web 🚀 Make smarter decisions with up-to-date data to fuel your AI and business strategies Every finance class my professor asks the class about current events in the world of finance and before when I used GPT it wouldn't give me as up to date information, more so info from last year (because that's how far up to date it was with information) which wouldn't really help me talk about the current landscape of finance. Now I can be a finance expert in real time! Try it out today and level up your research! Let us know how it’s helping you.
2
1
New comment 23d ago
25d ago in
✏️ Leveraging AI as an Extension of Human Potential
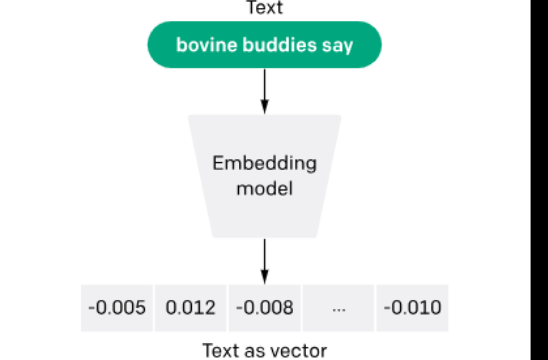
Happy Sunday! Wanted to drop this article because it really helped me understand how LLM's are able to consistently output sequential pieces of text with continuously improving accuracy. On page 3, I got confused about embedding models, but the picture that I attached below really helped me visualize that process. In my annotations, I explore key points about how AI functions as a powerful tool to extend human capabilities—helping to enhance critical thinking and streamline complex processes, while still relying on human oversight and expertise. I was particularly interested in how the article frames AI as a complement to human intelligence rather than a replacement, emphasizing that AI’s true potential lies in how we use it to augment our own skills and knowledge. Here's the link to the blank article and my annotated version: Keep Exploring, Josh
2
0
29d ago in
Tool Spotlight: Gamma.app – Create Presentations in Minutes!
Just saw my roommate create a real estate presentation in under 5 minutes with Gamma.app—an AI-powered tool that makes stunning presentations, documents, and websites with zero design skills needed. 🚀 Gamma handles the design, applies expert layouts, and helps rewrite or autocomplete your content. It also offers dynamic charts, interactive galleries, and mobile-friendly sharing with built-in analytics. If you want to save time while delivering polished, professional presentations, check out Gamma: https://gamma.app Here's their demo video: https://youtu.be/vtMIUtE9doQ?list=TLGGeYDtlYo_XysxNjEwMjAyNA
3
0

Oct 14 in
🎥 Meta’s MovieGen: Raising the Bar for AI-Generated Video Content
Hey AI Explorers! 🌟 One of the most exciting AI innovations of this week is Meta’s MovieGen. This powerful tool is part of the growing trend of multimodal AI, which means it can create both synchronized audio and video from simple text prompts! Imagine generating a professional-quality video for your next marketing campaign or creative project without spending hours on editing—it’s all done with AI. Here's the landing page with example videos from Meta: https://ai.meta.com/research/movie-gen/ I don't believe that MovieGen is avalible to the public yet, but of course you can use other tools to make realistic AI videos. It's just interesting because in addition to OpenAI's Sora, creatify, and these other companies that have put their time and attention into creating AI videos, Meta has spent large amounts of resources working to gain market share as well. The 2 main things that i've seen set it apart is the video length feature & the integration of AI videos into social media. Meta's working to make their videos long form (at least a minute). Here's a quote from the whitepaper talking about the competition and how their videos are only 15 seconds: "There are a few products offering video-to-audio capabilities, including PikaLabs4 and ElevenLabs.5, but neither can really generate motion-aligned sound effects or cinematic soundtracks with both music and sound effects. PikaLabs supports sound effect generation with video and optionally text prompts; however it will generate audio longer than the video where a user needs to select an audio segment to use. This implies under the hood it may be an audio generation model conditioned on a fixed number of key image frames. The maximum audio length is capped at 15 seconds without joint music generation and audio extension capabilities, preventing its application to soundtrack creation for long-form videos. ElevenLabs leverages GPT-4o to create a sound prompt given four image frames extracted from the video (one second apart), and then generates audio using a TTA model with that prompt. Lastly, Google released a research blog6 describing their video-to-audio generation models that also provide text control. Based on the video samples, the model is capable of sound effects, speech, and music generation. However, the details (model size, training data characterization) about the model and the number of samples (13 samples with 11 distinct videos) are very limited, and no API is provided. It is difficult to conclude further details other than the model is diffusion-based and that the maximum audio length may be limited as the longest sample showcased is less than 15 seconds."
4
4
New comment 29d ago

1 like • 29d
@Johnathan Bell no it's not public. Bing news & tech radar both say Sora launch was supposed to be on Dev Day but obviously that didn't happen so its up for speculation when it's going to actually launch

Oct 14 in
🚨New tool 🚨Project Neo release
Adobe just debuted with their “Project Neo” beta allowing us to create a multitude of different variations of designs quickly natively in the adobe suite, and also convert those designs into 3D scenes. Think of it as a cracked meshy AI for Adobe. Take a few minutes to watch this video to see the potential use cases that you could implement! Keep exploring, Reece
2
2
New comment 29d ago

0 likes • 29d
the changing of the texture was really the most insane thing to me
1-10 of 14

@joshua-bell-8188
Founder of Profit Processes - profitprocesses.com | We help wealth managers book appointments with millionaires without them lifting a finger.
Active 2d ago
Joined Sep 18, 2024
powered by